






pandas学习
主要参考书目:《利用python进行数据分析》^1
学习目标
- 了解Pandas的特点
- 熟悉Pandas的基本数据结构以及其属性
- 掌握pandas的数据创建、导入导出、索引、切片、拼接、转化这几项基本操作
- 掌握DataFrame的Index Column的相关操作(Reindex、Sort)
- 学习Pandas的数学运算
- 掌握Category类型和groupby方法
学习笔记
Pandas特点
- 基于numpy实现,属于scipy科学计算包
- 很方便实现对一维数据、二维数据的数据分析
- 方便进行数据可视化
- 索引方式灵活(允许简单索引与多级索引)
- 实现了对缺失数据的处理
基础数据结构
主要介绍三个数据结构:Index、Series、DataFrame(其实还有个Panel三维数据结构)
1. Index
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。Index对象不可修改,从而在多个数据结构之间安全共享。
注意:
- pandas的Index允许索引重复
- 不只是int还可以是string
2. Series
一维数据结构
允许不同类型的数据(此时dtype为object)
初始化的时候可以指定Index
初始化可以传list+index,也可以是dict、np一维ndarray类型、标量填充
若index和data中的索引不完全一致,最终生成的Series的index按照index参数
3. DataFrame
- 初始化:
- dict => {‘name’:Series}
- ndarray(ndim=2)
- 初始化参数(data、index、columns)
- 缺失值会用NaN填充
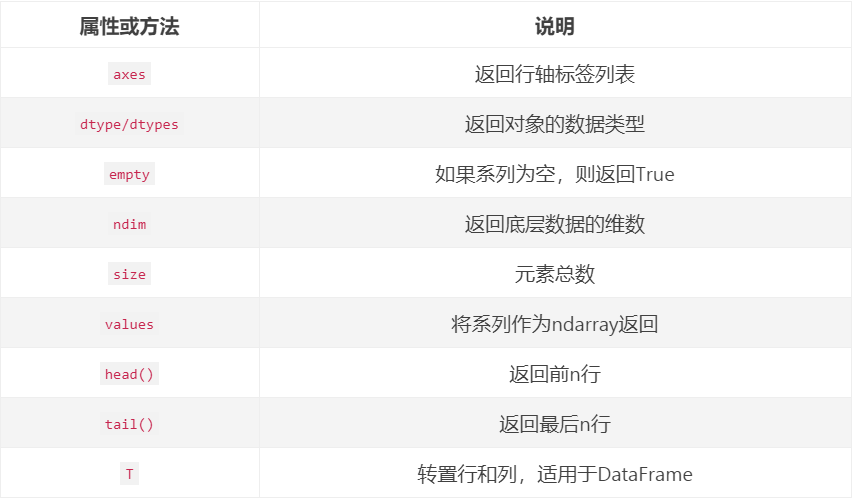
常用属性&方法汇总
导入导出
pandas支持的导入导出非常多
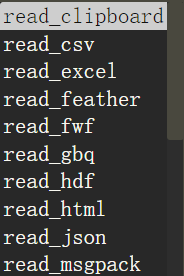
常见的有:
pd.read_csv
pd.read_excel
pd.read_json
pd.read_pickle
pd.read_sql
pd.read_table
使用方法(read_csv):
data = pd.read_csv('file.csv',dtype=object)
常用dtype:int64 float64 object category
注意传进来的数据类型常常是不满足要求的,一般需要进行类型转换甚至是数据预处理
索引&切片
主要有三种索引方式:[]、loc、iloc
对于DataFrame,可以直接用df.col的形式取某一列
loc
.loc主要是基于标签(label)的,包括行标签(index)和列标签(columns),即行名称和列名称,可以使用df.loc[index_name,col_name],选择指定位置的数据,其它的用法有:
- 使用单个标签。如果.loc[]中只有单个标签,那么选择的是某一行。 df.loc[3]选择的是index名为‘3’的一行,注意这里的’3’是index的名称,而不是序号
- 使用标签的list:同样是只选择行
- 标签的切片对象:与通常的python切片不同,在最终选择的数据中包含切片的start和stop
- 布尔型的数组:通常用于筛选符合某些条件的行
- 也可以是函数(lambda)
iloc
iloc是基于位置的索引,利用元素在各个轴上的索引序号进行选择,序号超出范围会产生IndexError,切片时允许序号超过范围,用法包括:(和loc的用法基本一样)
- 整数
- 单个list or ndarray(对行选择)
- 切片
- 。。。
[]
- 只能索引列
- 索引多列同样传个list
拼接
拼接当出现没有匹配时默认NaN填充,当出现重复
扩充行列时可以直接用
df['new_col'] = df.Series()
df.iloc[-1] = list()
两个df组合时候使用concat、merge和join方法^2
concat
pd.concat([df1, df2], axis=0) # 可以设置axis,axis=1表示左右拼接
merge
这块还是要补补数据库部分的知识,忘得差不多了😂
join和merge差不多,但是join是DataFrame内置方法,直接df1.join(df2)即可
pandas的merge方法是基于共同列,将两个dataframe连接起来。merge方法的主要参数:
- left/right:左/右位置的dataframe。
- how:数据合并的方式。left:基于左dataframe列的数据合并;right:基于右dataframe列的数据合并;outer:基于列的数据外合并(取并集);inner:基于列的数据内合并(取交集);默认为’inner’。
- on:用来合并的列名,这个参数需要保证两个dataframe有相同的列名。
- left_on/right_on:左/右dataframe合并的列名,也可为索引,数组和列表。
- left_index/right_index:是否以index作为数据合并的列名,True表示是。
- sort:根据dataframe合并的keys排序,默认是。
- suffixes:若有相同列且该列没有作为合并的列,可通过suffixes设置该列的后缀名,一般为元组和列表类型。
# 单列的内连接
# 定义df1
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# print(df1)
# print(df2)
# 基于共同列alpha的内连接
df3 = pd.merge(df1,df2,how='inner',on='alpha')
df3
转换
主要内容:
DataFrame转numpy或dict、list^3
df.values df.as_matrix() np.array(df)DataFrame内类型转换
df.dtypes查看数据类型
astype转换数据类型
df['col2'] = df['col2'].astype('int')
行列索引操作
sort (按index排序:sort_index; 按value排序:sort_values),如果只是拿到一个排名Series,使用rank方法
df.sort_index( axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None, ) df.sort_values( by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', )rename
reset_index舍弃乱的index,重新生成,旧的index会成为一个新的columnreindex行列顺序重新指定,若出现新的行列会NaN填充result3 = result.reindex(columns=['A','C'])
常见数学运算
df.describe()cov cor
apply applymap
apply(fun, axis=’index’)
### groupby&Category[^4]
Category主要是将长字符串类别名称转为类别标号存储,减少存储空间
```python
pd.Categorical(['a','b'])
# or
df['col'].astype('category')
groupby进行分组操作
df.groupby(Series or 'name') # 根据Series或者name字段分组
其他方法
one-hot(独热编码)
pd.get_dummies(series)value_counts
统计某个series每个分类值的数量

