






PRML-回归线性模型
- PRML
- 回归线性模型
本章主要将的是使用线性模型进行回归的问题,首先讲线性模型、回归问题的基本概念,其中涉及基函数等重要概念;接下来从几个不同的视角来看线性回归模型求解算法(最小二乘):极大似然估计、几何视角;接下来主要讨论模型的复杂度这个问题,从频率学派和贝叶斯学派分开讨论,对于频率学派来说,通过对于目标函数期望损失的分解(偏置-方差分解),得到模型的复杂度变化对于偏置、方差的影响。
接下来讨论贝叶斯线性回归,但介绍此内容之前,先介绍了正则化和顺序学习方面的内容,这部分实际和贝叶斯线性回归也有密切的关系。贝叶斯线性回归的一个重要问题实际上还是先验的确定,这里实际上是为了数学上的简洁性,把先验定为零均值的高斯分布(也就是先验不是通过数据确定的);接着又从数据的角度分析贝叶斯线性回归模型的不确定性,“预测的不确定性依赖于输入变量,数据点邻域处的不确定性小”。
接下来“等价核”、贝叶斯模型比较证据近似等内容先略过,后续再补充。
有待学习的知识点:
- 概率分布(CH02)
- 共轭先验
- 边缘似然
主要知识笔记
一、线性回归模型介绍
回归问题
线性模型
基函数
二、线性回归模型学习算法
1.直观:最小二乘估计
误差函数与损失函数
损失函数在第一章决策论中提出一个最小化期望损失$\mathbb{E}[L]=\sum_{k} \sum_{j} \int_{R_{j}} L_{k j} p\left(\mathbf{x}, C_{k}\right) \mathrm{d} \mathbf{x}$;在推断中,只需要寻找目标变量的最大后验概率$\mathbf{argmax}{k} L{k j} p\left(C_{k} \mid \mathbf{x}\right)$。
误差函数是手工设计的目标函数,通常将其设计为与MLE有等价解的函数。
在1.5.5回归问题的损失函数一节中,对于回归问题,从使用了平方损失作为损失函数,并分解如下(这个期望损失可以看作自变量$y$的函数,理想情况下当取得最优解是第一项为0,但实际数据集是指定的,因此第一项无法完全消除,后续会将第一项分解,只剩下关于最优预测与gt的项)
$$
h(\mathbf{x})=\mathbb{E}[t \mid \mathbf{x}]=\int t p(t \mid \mathbf{x}) \mathrm{d} t
$$
$$
\mathbb{E}[L]=\int{y(\mathbf{x})-\mathbb{E}[t \mid \mathbf{x}]}^{2} p(\mathbf{x}) \mathrm{d} \mathbf{x}+\int\int{\mathbb{E}[t \mid \mathbf{x}]-t}^{2} p(\mathbf{x},t) \mathrm{d} \mathbf{x} \mathrm{d} t
$$
大概可以看到总的损失为数据的噪声方差损失与模型的偏差平方和损失构成。
平方和误差函数和平方损失函数之间一个是面向数据点做求和,另一个是理想的对联合分布积分,两者实际上是一个东西在两个侧重点的不同叫法。
第一章中的多项式拟合问题中,使用了最小化平方和误差函数作为确定参数的目标函数,这里将从几何角度和概率角度解释这个误差函数
$$
E_{D}(\mathbf{w})=\frac{1}{2} \sum_{n=1}^{N}\left{t_{n}-\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}\left(\mathbf{x}_{n}\right)\right}^{2}
$$
2.概率解释:高斯噪声假设下的极大似然估计
假设数据集为$(\mathbf{X,T})$,目标变量t由输入变量的线性函数$y(x,w)$给出,且假设数据服从高斯噪声$\epsilon \sim N(0,\beta^{-1})$
$$
t=y(x,w)+\epsilon
$$
对于一个新的输入变量,目标变量可以用条件均值来估计
$$
\mathbb{E}[t \mid \mathbf{x}]=\int t p(t \mid \mathbf{x}) \mathrm{d} t=y(\mathbf{x}, \mathbf{w})
$$
利用极大似然估计来确定参数,首先写出似然函数,取对数后有
$$
\begin{aligned}
\ln p(\mathbf{t} \mid \mathbf{w}, \beta) &=\sum_{n=1}^{N} \ln \mathcal{N}\left(t_{n} \mid \mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}\left(\mathbf{x}{n}\right), \beta^{-1}\right) \
&=\frac{N}{2} \ln \beta-\frac{N}{2} \ln (2 \pi)-\beta \frac{1}{2} \sum{n=1}^{N}\left{t_{n}-\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}\left(\mathbf{x}_{n}\right)\right}^{2}
\end{aligned}
$$
记误差函数为
$$
E_{D}(\mathbf{w})=\frac{1}{2} \sum_{n=1}^{N}\left{t_{n}-\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}\left(\mathbf{x}_{n}\right)\right}^{2}
$$
算出最小平方和误差函数和极大似然估计的解析解都为
$$
\mathbf{w}_{\mathrm{ML}}=\left(\mathbf{\Phi}^{\mathrm{T}} \mathbf{\Phi}\right)^{-1} \mathbf{\Phi}^{\mathrm{T}} \mathbf{t}
$$
其中$\Phi$为设计矩阵形式如下
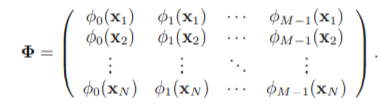
因此,最小平方和误差函数的解析解和高斯噪声下极大似然估计算出的解结果相同
3.几何解释:最小平方和的几何描述
N个数据点的数据集(每个数据点有d个维度)看作N维空间中的d个向量,这d个向量可以看作基向量,形成张成空间S,N个目标变量T同样构成一个向量t;最小平方和误差函数等于S到t的距离的平方,相当于原问题就是找t在S上的投影。
三、顺序学习&正则项
1.顺序学习
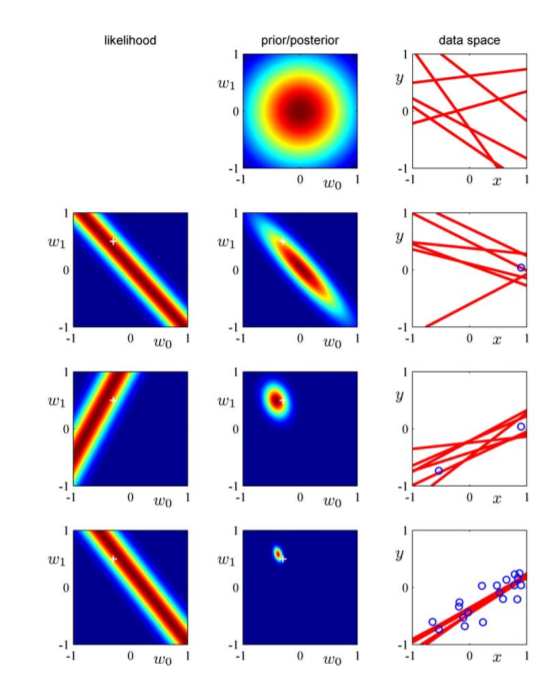
有两个顺序学习,一种是频率下的顺序学习(SGD),好处有二,一是顺序学习可以做成实时算法,数据边采集边学习;二是当解析解不好计算(数据量高的时候由于矩阵计算复杂度也大导致计算时空开销巨大)时可以采用顺序学习降低计算复杂度。另一种是贝叶斯下的顺序学习,就是不断获取新的evidence并更新posterior。
- 顺序学习
频率视角下的参数更新
- 参考SGD算法
- 优点
- 实时
- 传统算法在数据量大的时候矩阵运算时空开销非常巨大
贝叶斯视角下的参数更新
- 不断获取新的evidence并更新posterior
2.正则项
正则化方法
使用正则的目的是控制过拟合,降低模型复杂度
常见的正则有L1、L2、L1L2
正则化方法有时被称为权值衰减,因为其倾向于让权值向零方向衰减
线性回归模型正则化
在误差函数中加入正则项
$$
E(\mathbf{w})=\frac{1}{2} \sum_{n=1}^{N}\left{t_{n}-\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}\left(\mathbf{x}{n}\right)\right}^{2}+\frac{\lambda}{2} \sum{j=1}^{M}\left|\mathbf{w}_{j}\right|^{q}
$$
- $q=1$时为Lasso回归:趋向于形成更稀疏的模型(模型复杂度降低程度大)
- $q=2$时为Ridge回归
此外,正则化方法也可以用贝叶斯线性回归来解释,将在后续内容中讨论
四、模型复杂度分析
这部分是分析期望损失的构成以及控制模型复杂度对于结果的影响
偏置-方差分解
此前对于期望损失的分解如下
$$
\mathbb{E}[L]=\int{y(\mathbf{x})-\mathbb{E}[t \mid \mathbf{x}]}^{2} p(\mathbf{x}) \mathrm{d} \mathbf{x}+\int\int{\mathbb{E}[t \mid \mathbf{x}]-t}^{2} p(\mathbf{x},t) \mathrm{d} \mathbf{x} \mathrm{d} t
$$
对于特定数据集D,第一项还可以展开成
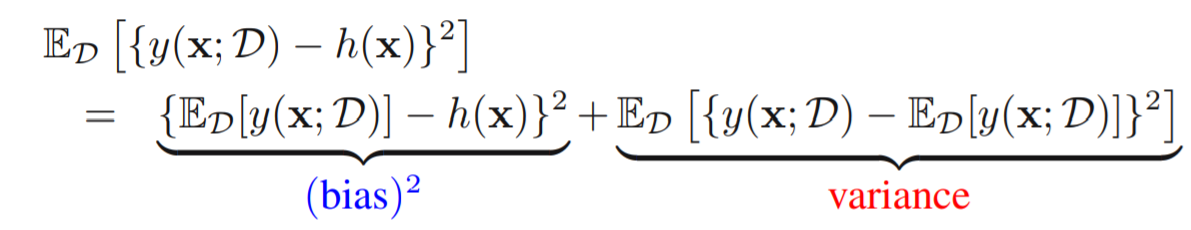
重新分解期望损失
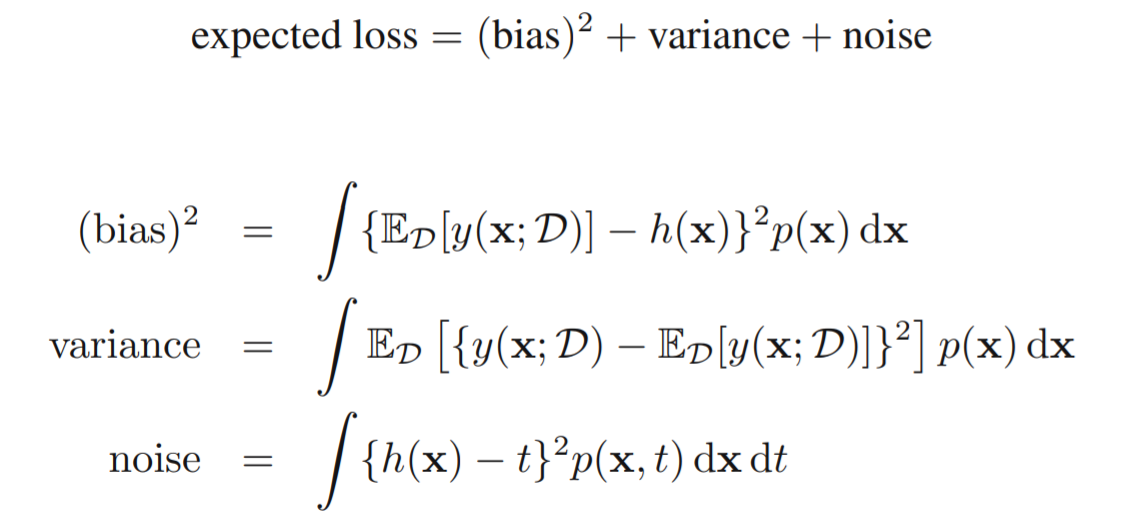
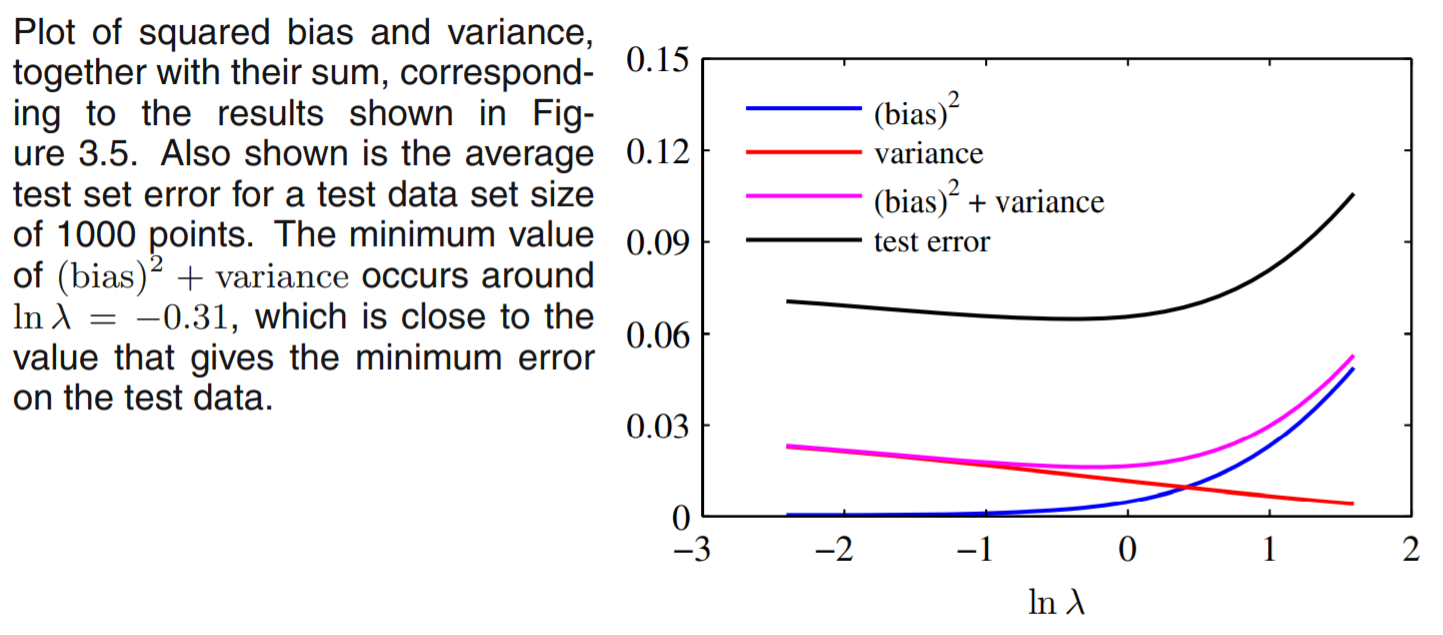
期望损失分解成3部分:基于特定数据集的期望预测模型与最优预测模型之间偏差的平方、特定数据集内预测模型的方差、最优预测与gt形成的噪声。
当模型复杂度变化时,期望损失也会发生变化:
模型复杂度升高,方差项升高
模型复杂度升高,偏差平方项降低
贝叶斯线性回归
贝叶斯线性回归中,我们用概率来建模参数的更新过程,求的是关于X,y的参数最大后验概率;在之前的线性回归中,用条件概率、条件期望分析的是对目标变量的估计,也可以认为求关于X,y的极大似然。也会引出使用训练数据本身确定模型复杂度的自动化方法。
极大后验概率的
- 正则化操作的另一种解释
- 参数分布先验
贝叶斯线性回归中,假设参数是随机变量,服从某一分布,根据共轭先验参数服从高斯分布,为了数学上的形式简洁,假设参数服从0均值、各向同性的高斯分布,计算MAP
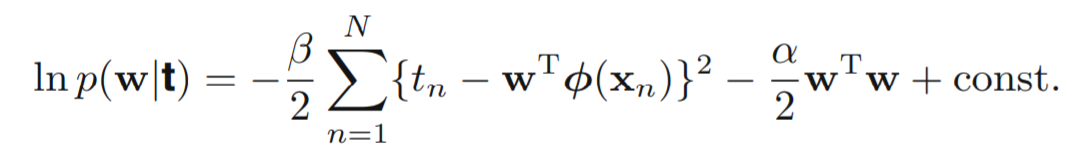
得到与正则化一致的结果
$$
\begin{aligned}
\mathbf{m}{N} &=\mathbf{S}{N}\left(\mathbf{S}{0}^{-1} \mathbf{m}{0}+\beta \mathbf{\Phi}^{\mathrm{T}} \mathbf{t}\right) \
\mathbf{S}{N}^{-1} &=\mathbf{S}{0}^{-1}+\beta \mathbf{\Phi}^{\mathrm{T}} \mathbf{\Phi}
\end{aligned}
$$
以上是对于参数$w$的估计部分,现在需要考虑预测$p(t|\mathbf{t},\alpha,\beta)$的分布情况
$$
p(t|\mathbf{t},\alpha,\beta)=\int p(t|w,\beta)p(w|\mathbf{t},\alpha,\beta){\rm d} w = \mathcal{N}\left(t \mid \mathbf{m}{N}^{\mathrm{T}} \boldsymbol{\phi}(\mathbf{x}), \sigma{N}^{2}(\mathbf{x})\right)
$$
可以给出输入空间中任一点的协方差估计
$$
\sigma_{N}^{2}(\mathbf{x})=\frac{1}{\beta}+\phi(\mathbf{x})^{\mathrm{T}} \mathbf{S}_{N} \phi(\mathbf{x})
$$
这个估计可以视作模型在此处的不确定性,直观地讲,一个地方的数据点越密集、同时这些数据点之间的方差越小,该位置的不确定性越小。


