Deep Cross-Modal Projection Learning for Image-Text Matching

ECCV 2018
Question
- 是否有论文用Attention来做这件事?DAN(那我们这个思路还有什么意义?)
- 如何进行解释?Grad-CAM等方法如何融入其中?
- 训练过程的样本选择这篇论文没讲
- Case Study(感觉预训练的分类网络只有对象的判别能力,没有相对位置的识别能力,可以用一对位置相反的对象图来验证这个事)
- 这个问题感觉能改的地方主要在跨模态的loss设计以及样本选择上
TODO
- Learning deep structure-preserving image-text embeddings paper reading
- Dual attention networks for multimodal reasoning and matching paper reading
- Finding beans in burgers: Deep semantic-visual embedding with localization paper reading
本文工作
- 提出两个loss(跨模态投影匹配损失 CMPM loss; 跨模态投影分类损失 CMPC loss)来学到更有判别性的嵌入表示,提升匹配精度
Related Work
目前采用深度学习进行图像描述匹配的方法可以分成两类:
联合嵌入表示学习
寻找公共隐空间
- correlation loss
- bi-directional ranking loss:基于三元组损失(所以主要问题是负样本选择于margin值的设置)
- DCCA(深度典型相关分析):存在的问题是每个minibatch的协方差估计不稳定
成对相似度学习
直接学习如何判别两者是否匹配
这部分研究也分成两部分
- 全局相似度:直接判别图像与描述的相似度
- 局部相似度,对齐描述中的文字与图像切片内容
现有的学习joint embedding的方法(4个):
- Learning deep structure-preserving image-text embeddings(cvpr 2016)
- Learning two-branch neural networks for image-text matching tasks(TPAMI 2018)
- Deep correlation for matching images and text(CVPR 2015)
- Learning a recurrent residual fusion network for multimodal matching(ICCV 2017)
这些方法都是采用学习图片和描述在隐空间中的联合嵌入表示或者建立一个相似度学习网络(直接算相似度得分),其中前者效果要好(速度快,效果好)
这些方法的机制图如下
通常的流程
首先图片和描述各自抽取嵌入表示
接下来使用精心设计的目标函数将原始embedding转化成discriminative cross-modal embeddings
常用的函数如:CCA(canonical correlation analysis)、bi-directional ranking loss
identity-level annotations cross-modal matching method
- Learning deep representations of finegrained visual descriptions(CVPR 2016)
- Identity-aware textual-visual matching with latent co-attention(ICCV 2017)
- 两阶段训练方法,先用CMCE loss训一下,然后fine-tune
- Person search with natural language description(2017 CVPR)
- 提出跨模态交叉熵(CMCE)
对于深度度量学习,研究的最热的当然是人脸识别和ReID问题主要有两派:
- Softmax loss的各种变体损失
- 三元组loss的各种变体损失
度量学习存在的主要问题:
- 样本选择(如三元组损失中的正负样本对的选择比较有讲究)
- 模型对于margin参数比较敏感
- 对于多模态问题前面的方法不一定很适用
预备知识
CCA
常见度量学习损失
t-SNE
Method
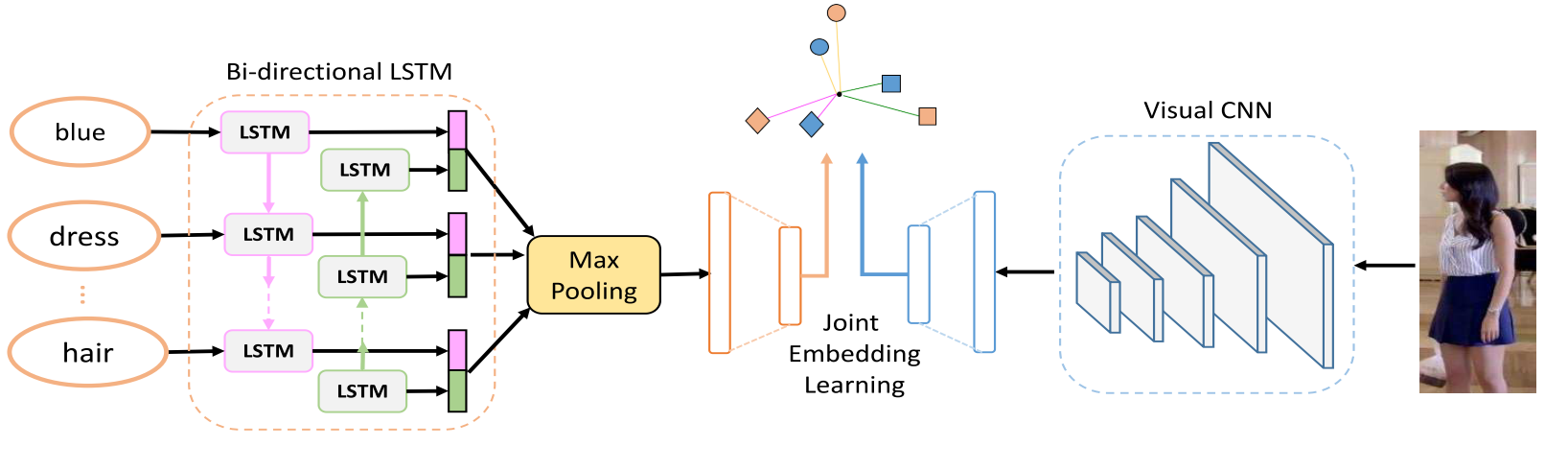
网络结构
和前面的机制图一样,一个CNN、一个Bi-LSTM、一个联合学习模块
backbone:
- MobileNet
- Bi-LSTM
Loss
CMPM loss > 最小化KL散度(projection compatibility distributions and the normalized matching distributions)
CMPC loss > categorize the vector projection of representations from one modality onto another with the improved norm-softmax loss
CMPM Loss
预测匹配概率p
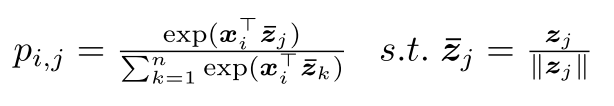
这里图片特征与描述特征的内积越大表示x在z上的投影长度大,表示两者的相似度越高;其中z为归一化的描述产生的特征向量。当图像i与描述j匹配时,p趋近于1/c(c个对应i的描述),其他不匹配的趋近于零
真实分布q

用来对匹配概率进行规范化,使得mini-batch中某个有多个图片-描述对的图片权值(也可以看成是某个图片i对于batch中所有描述是否匹配的分布)
损失

总的损失可以看成预测分布p与真实分布q的KL散度,其中$\epsilon$用来防止除0的。
Note
为什么是KL(p||q),而不是KL(q||p)?
- 因为q本身的分布不是one-hot型的,CE Loss会让p中高概率的值逼近q的值,但是q的值由于不是1,所以逼近的效果不太好(感觉这是建模成KL散度的问题,反过来也不能解决这个问题)
- “will be further demonstrated in experiments.”
bi-directional CMPM loss

在训练中是同时考虑image2text和text2image的,即CNN得到的图片表示和LSTM学到的文本表示都要主动转变到对方的空间中。
CMPC Loss
在loss上加入分类损失的目的是帮助每个模态学到的特征更具有判别性
具体细节
提出了一个norm-softmax loss来改进softmax loss,就是将权值的范数限制为1。然后仍旧是两个loss
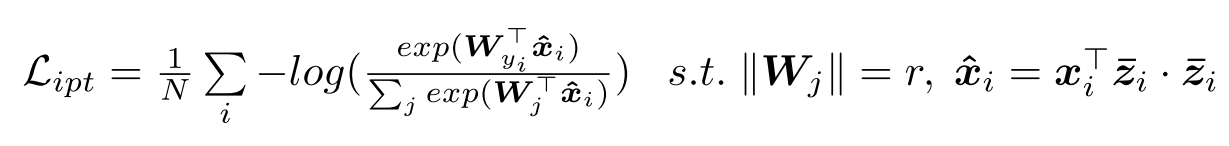

在inference阶段,首先用各自的模型去抽取特征,然后计算特征之间的余弦距离
实验结果
数据集
- Flickr30k
- MSCOCO
- CUHK-PEDES
- Caltech-UCSD Birds
- Oxford102 Flowers
评估
Recall
AP@50
结果

DAN要看一下😂
此外还做了消融实验来分析两个loss的贡献,但是用的数据集比较小。
还比较了KL散度方面的内容,并且调节不同的batch size大小,说明他们的loss设计得更好,而且CMPM+CMPC的loss对batch size也更不敏感。
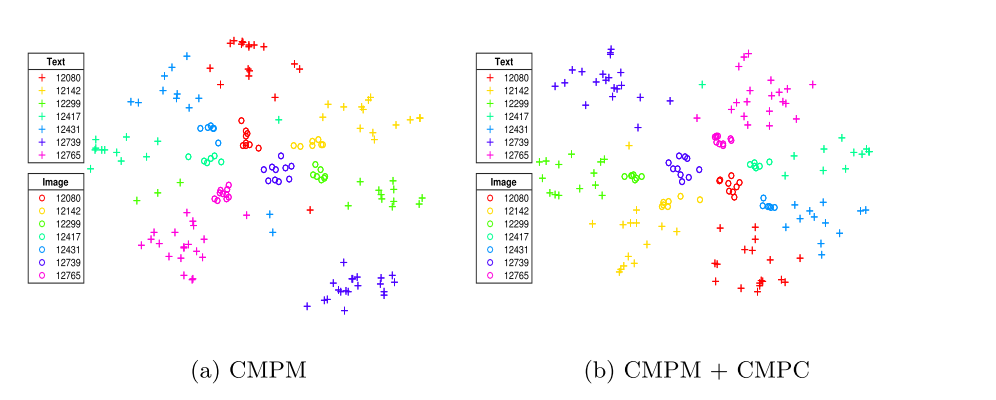
特征可视化
想看看抽取的特征是否能直观地看出有判别能力,使用t-SNE进行降维