






Stacked Cross Attention for Image-Text Matching
微软
SCAN主要贡献
- 结合并改进DVSA,VSE++,DAN三个的工作,取得了非常不错的结果
- 用不同于DAN的方式引入Attention机制以及采用多模态对齐提升了模型可解释性,解决了DAN只能关注固定数量attention region的问题
具体改进
DVSA:
采用更强大的检测模型Faster RCNN(backbone:ResNet-101),同时检测预训练模型不止学习检测显著对象,还要加入属性的学习(如毛茸茸、。。。)
VSE++
损失函数采用加入难样本挖掘的Max hinge loss,同时经过消融实验发现,该模型对于loss比较敏感,换成Sum hinge loss掉了22个点
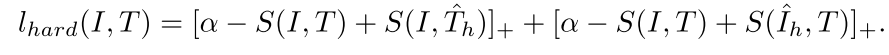
Attention
这里应该不算借鉴DAN的方法,而是从DVSA的基础上设计新的Attention机制,具体好像借鉴了《Bottom-up and top-down attention for image captioning and VQA》 这篇工作
这里展开介绍一下:
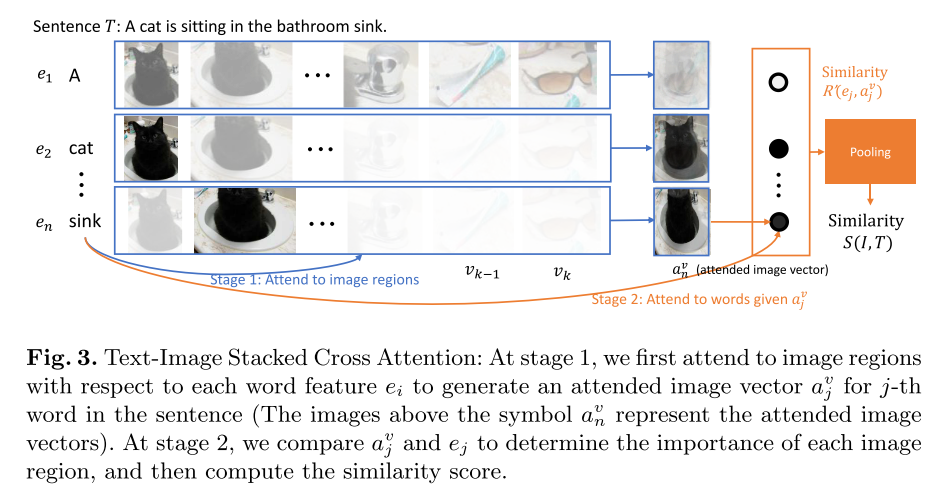
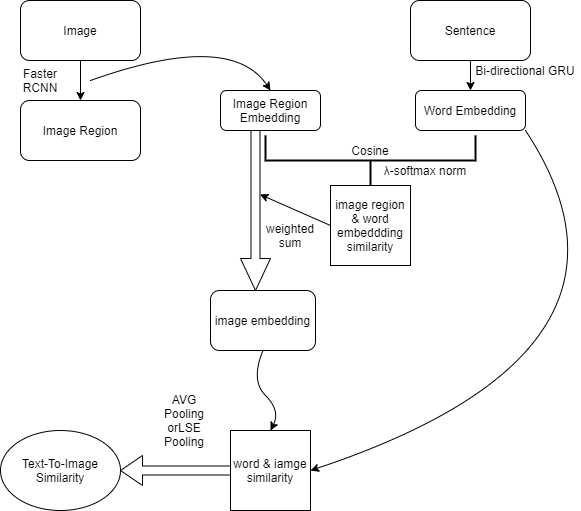
首先这个Attention对称地分成两部分Image-To-Text和Text-To-Image ;先介绍Image-To-Text的方法
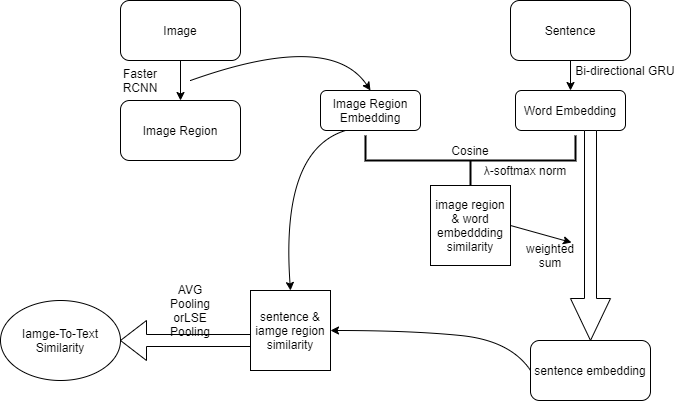
如下图,在经过Faster RCNN将image划出若干个region后,Fast RCNN的第二个阶段的最后一个avg pooling层连一个fc层,产生image region的embedding,再拿这些image embeddings和word经过双向GRU后算出的word embedding进行相似度计算(这里采用cosine similarity),得到image region对word的响应矩阵(类似DVSA),算出的相应权重会经过公式3的λ-softmax在sentence上进行归一化
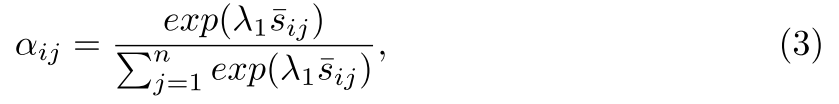
拿归一化后的权重对word embedding做加权求和作为sentence的相似度,这个相似度再和之前的image embedding算image region和sentence的相似度,最后拿image region和sentence的相似度做pooling得到整体的相似度。
训练时Faster RCNN部分的参数固定住,只需要学习抽image embedding的fc层以及双向GRU就行

注意这里的word embedding指的是经过双向GRU的embedding,不用训练好的embedding的原因是缺少这些训练好的embedding matrix缺少上下文信息


思考一下整个Attention过程,做了一个流程图如下
Text-To-Image的Attention同理
两种pooling方法,后续实验给出了最佳的组合配置:

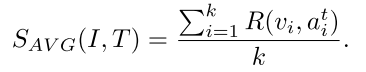
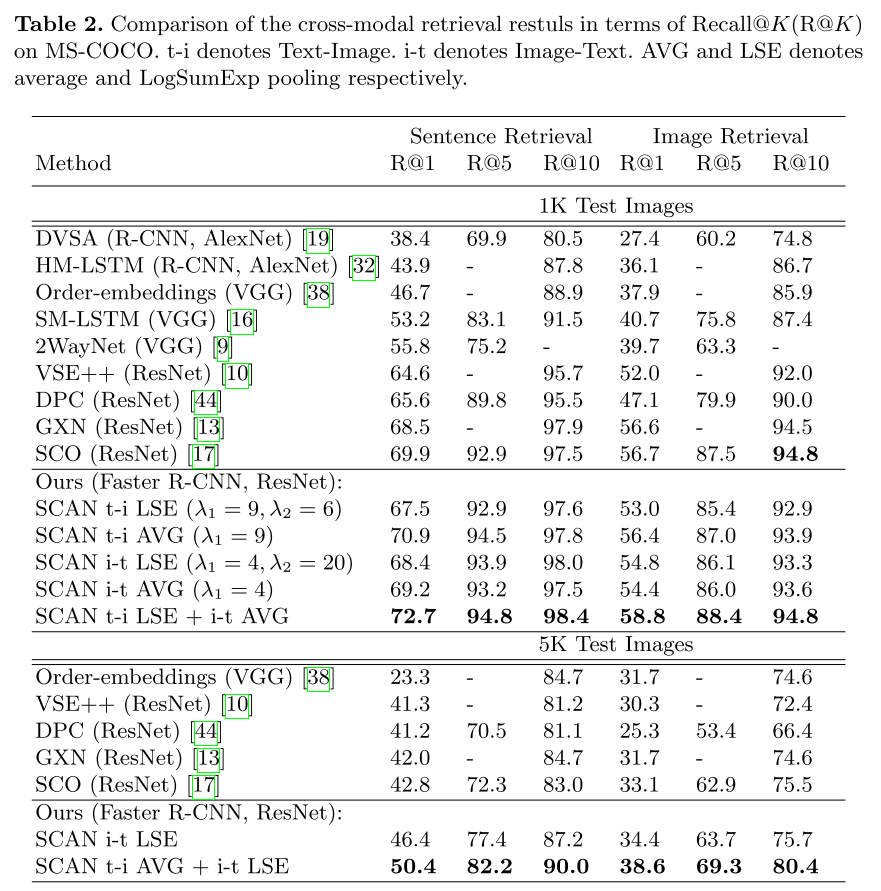
结果
Flickr30k

MS-COCO(MS的论文居然不把MS-COCO放在第一个实验😂)
另外论文还通过attention产生的显著图进行可解释分析以及可视化,和自己要做的东西关系不大,就不放了。。

