






Self attention工作两篇
最近在看自注意力的工作,要把这个加到现有的模型中,先记录一下两篇引用量比较高的工作
Outline
- Self Attention
- A Structured Self-Attentive Sentence Embedding
- Non-local Neural Networks
Paper Reading
A Structured Self-Attentive Sentence Embedding
2017 ICLR Bengio
主要工作
提出的模型主要是针对从词嵌入获得句子嵌入表示的,在这个过程中加入自注意力机制
提出了一个新的通过自注意力机制提取(集成)句子embedding的方法,使用矩阵表示句子embedding
sentence embedding matrix
- each row vector represent a different part of the sentence
- 可以很方便地进行可视化(part与word的对应关系)
task
- author profiling
- 情感分类
- textual entailment
贡献
- 提出自注意力机制
- 使用自注意力获取句子embedding
- 提出一个特别的正则项
背景
此前的提取sentence embedding的方法不是很好,这些方法大致可以分成两类:
- universal sentence embeddings usually trained by unsupervised learning: Skip-Thought vectors、ParagraphVector、recursive auto-encoders、Sequential Denoising Autoencoders、FastSent
- trained specifically for a certain task(这种方法得到的embedding一般来说比前者好),这种方法通常用max pooling或者mean pooling提取sentence embedding或者N-gram卷积或者用最后time step的输出作为句子的表示
方法
self-attention
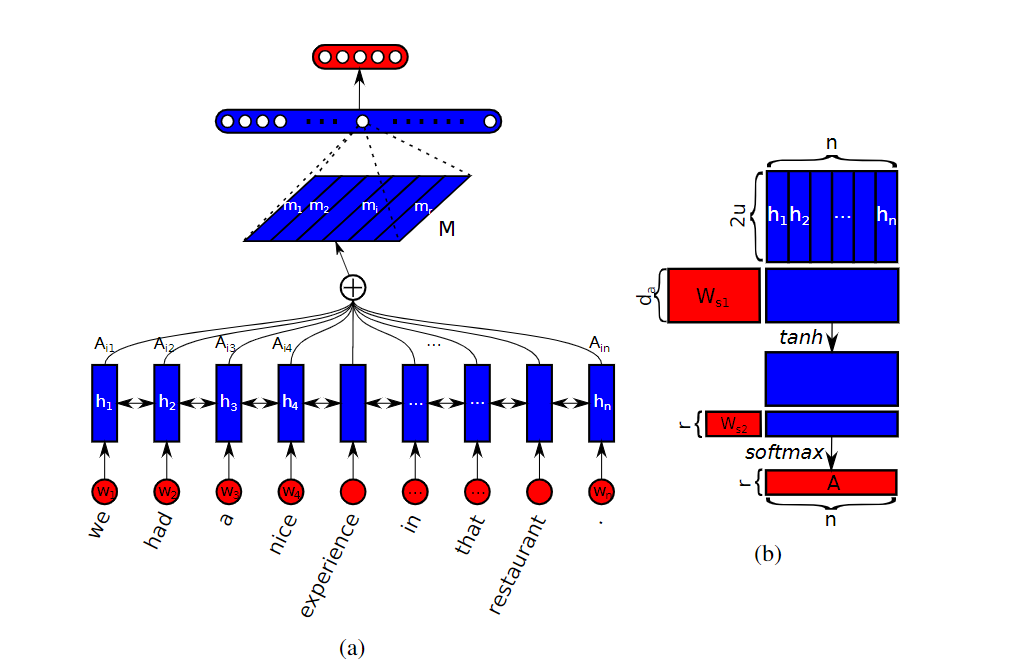
上图是注意力向量获取方法,拿到注意力向量之后对wordembedding进行加权⊕
$$
a=\operatorname{softmax}(w_{s 2} \tanh (W_{s 1} H^{T}))
$$
这里既可以输出一个attention vector,也可以输出multi-head attention
$$
A=\operatorname{softmax}\left(W_{s 2} \tanh \left(W_{s 1} H^{T}\right)\right) \
M=AH
$$
在加入multi-head attention之后,希望这些attention尽可能关注不同的内容,所以需要加入惩罚项进行学习
The embedding matrix M can suffer from redundancy problems if the attention mechanism always provides similar summation weights for all the r hops. Thus we need a penalization term to encourage the diversity of summation weight vectors across different hops of attention.
$$
P=\left|\left(A A^{T}-I\right)\right|_{F}^{2}
$$
这一项让各个注意力权重向量尽可能正交,同时自身范数尽可能为1
摘录
注意力机制 use attention mechanism on top of the CNN or LSTM model to introduce extra source of information to guide the extraction of sentence embedding
This enables attention to be used in those cases when there are no extra inputs
We hypothesize that carrying the semantics along all time steps of a recurrent model is relatively hard and not necessary
Non-local Neural Networks
2018 CVPR, Ross Girshick Kaiming He
主要工作
和前面的论文不同,这篇论文使用注意力来做视觉的
摘录
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time
Convolutional and recurrent operations both process a local neighborhood, either in space or time
For image data, long-distance dependencies are modeled by the large receptive fields formed by deep stacks of convolutional operations
Repeating local operations has several limitations. First, it is computationally inefficient. Second, it causes optimization difficulties that need to be carefully addressed
In this paper, we present non-local operations as a generic family of building blocks for capturing long-range dependencies.
Our non-local operation computes the response at a position as a weighted sum of the features at all positions.
Intuitively, a non-local operation computes the response at a position as a weighted sum of the features at all positions in the input feature maps.
使用注意力机制来进行非局部特征融合
task
- 视频分类
- COCO 检测、分割、姿态估计
贡献
提出了一种非局部计算方法,提出模型 non-local neural networks
非局部操作的优势:
- 相比与堆叠的CNN、RNN,这种non-local 可以无视距离来提取long range dependencies
- 结果上看比此前的方法更有效
- 很容易加入到现有模型中
背景
问题
- 卷积结构和循环结构都阻碍了全局信息的获取,注意力机制能帮助解决这个问题
相关工作
从多个不同角度来讲相关工作,厉害厉害!
Non-local image processing
Non-local means方法
A non-local algorithm for image denoising(classical non-local means method) BM3D
Graphical models
通过图来建模长距离依赖,代表方法有:CRF、GNN
Feedforward modeling for sequences
用卷积代替RNN做序列问题
Self-attention
Attention is all you need在这个论文之前。。
our work bridges self-attention for machine translation to the more general class of non-local filtering operations that are applicable to image and video problems in computer vision
Interaction networks(Relation Network)
用和自注意力不同的另一个视角看这种非局部操作
方法
$$
y_{i}=\frac{1}{C(x)} \sum_{\forall j} f(x_{i}, x_{j}) g(x_{j})
$$
任意两个位置i和j通过pairwise function算一下类似权重的东西,然后对于特征图中所有点进行这样的加权计算,然后再用C函数进行归一化,这里g函数应该是一个j位置的输入信号的表示向量
和全连接的区别:fc的权重是网络学得的,non-local的权重$f(x_i,x_j)$是计算相应得到的;fc的权重是一个受位置固定的(对于任意两个位置,它们的fc权值是固定的),non-local的权重是与位置无关的(权值受具体输入信号影响);fc要求输入的size固定
具体的g函数可以是一个1x1的卷积操作
pairwise function $f$可以有很多种
Gaussian
f(x_i, x_j)=e^{{x_i}^T x_j}
Embedded Gaussian
f(x_i, x_j)=e^{\theta(x_i)^T \phi(x_j)}
在计算点积之前先乘个矩阵,这个可以用另一种与self-attention一致的方式表示:
$$
{y}=\operatorname{softmax}(x^T W_{\theta}^T W_{\phi} x) g(x)
$$
这个操作之后,相当于特征图中每个位置都有注意的区域的信息
此外还有直接点乘、concatenation等方法
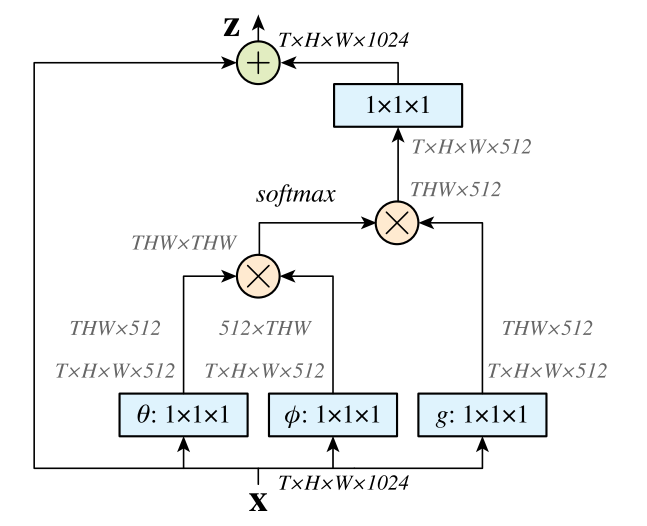
Non-local Block
$$
z_i=W_z y_i+x_i
$$
这里使用残差链接构成一个模块,这个模块很容易加入到其他视觉模型中,相当于每个位置的注意力表示和原来的输入表示做了个运算(加法运算。。)
计算图如下
分析
感觉这两个工作的self-attention的大致思路是:
- 首先有长距离依赖问题,需要有选择地获得某个位置对应的长距离依赖区域的表示
- 用响应函数以及归一化组合来获得注意力得分
- 用得分和得到的中间表示加权求和得到注意力表示
第一篇工作直接用注意力表示,而第二个工作通过残差链接的方式将注意力表示和原始表示又做了一个计算
第一篇论文不仅考虑了注意力得分的计算,还考虑了这个注意力需要加入惩罚项来防止每个学到的注意力权重都一样
自己的工作
首先先完成老师讲的文本端的self-attention,然后要考虑point到part这个过程如何用self-attention来拿到part embedding
感觉还要看看点云上的注意力机制的论文:
- PVNet: 基于注意力嵌入式的点云与多视角图像融合感知网络 MM 2018
- PCT: Point Cloud Transformer:清华团队将Transformer用到3D点云分割上后,效果好极了
- Relation-shape convolutional neural network for pointcloud analysis
貌似同期还有一篇Point Transform和PCT差不多?
