






PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation
TL;DR
提出了一个新的基于实例质心偏移量预测实例分割模型,模型首先通过一个两分支的预测网络(Backbone:3D U-Net),分别预测点云中每个点的语义分割类别和其相对于实例质心的偏移量,然后又分别用原始点云和预测出的质心点云分别进行聚类(类似于BFS、洪泛算法),接着还根据所聚的类对每个类分别送入他们设计的得分网络计算一个score,最后接一个点云上的NMS,进行实例分割。
该模型支持端到端的训练,主要可以分成三个部分:1)一个体素的3D U-Net,末端分别预测语义类别(CE loss)、质心偏移量(L1 loss + cosine loss) 2)Clustering Part 进行聚类 3)ScoreNet 预测是否能match到gt实例(soft label CE loss)。
相关工作
记录一些作者对于前述工作的看法与比较
点云特征提取方法
- MultiLayer Perception (MLP)-style network:PointNet PointNet++
- 3D Convoution:PointCNN
- Voxelize point cloud
2D实例分割方法分类
- Top-down
- Bottom-up
3D实例分割方法分类
- 基于检测的方法:GSPN
- 基于分割的方法:SGPN(embedding based method)
- 本文基于质心的方法
(这里作者没有提到一些对于本网络的创新有关系的 质心、偏移量类似的工作:VoteNet等)
方法
整体流程
We design a two-branch network to extract point features and predict semantic labels and offsets, for shifting each point towards its respective instance centroid. A clustering component is followed to utilize both the original and offset-shifted point coordinate sets, taking advantage of their complementary strength.

各模块分析
Backbone Network
将点云体素化,然后用3D-UNet进行特征提取,后面再还原回点云,后面接两个分支,分别预测语义类别和质心偏移量
这里UNet采用了两种卷积:Submainfold Sparse Convolution & Sparse Convolution
关于质心偏移量,作者给了一个统计,实例的点到质心的距离,大部分距离0.5m以内,实验上作者发现实例边缘上的点很难回归到质心,预测得不是那么准。因此,后面的对点的聚类作者用原始点云坐标和预测的质心坐标分别聚了一遍,相当于构造了两倍的候选实例类。

Clustering Algorithm
注意的是这里要将墙这种质心很难去预测的类删掉,这个算法本质上是一个枚举+BFS

ScoreNet

得到候选实例点集合之后,需要经过NMS过滤重复的候选集合,但是要送入NMS还缺少一个候选集合置信度,于是最后网络还有一个得分预测,输入是体素化的候选点集,送入一个小的U-Net网络,最后经过Max Pooling → FC Layer →Sigmoid得到预测得分,这里的gt还用soft label

结果
数据集
- ScanNet v2
- S3DIS
评价指标
mAP:这里整理一下mAP的计算
mean Average Precision,常用于目标检测结果的评估,这里也以目标检测来介绍mAP
目标检测中会预测出很多检测框,有些预测框和gt之间有很高的重合度、有的预测框附近没有gt框、有的gt和多个预测框都有较高的重合度
目标检测会有多个类别的检测AP,首先我们需要计算每个类的AP,对于所有类的预测AP求平均得到mAP
接下来介绍AP的计算:
我们首先需要计算每个预测框和gt的最大IOU,也就是找预测框最相近的gt框的IOU,我们这里有个阈值th,只有IOU大于th的最大预测框才被视为TP,其余的都是FP

然后根据每个框的置信度从小到大排序(这个置信度不是max IOU,而是我们的模型的阈值,超过这个阈值的预测框才被输出出来)

排序后的结果,同时做一个统计,计算累计的Acc TP FP,得到了在该阈值下的Precision和Recall

然后作P-R图

AP有两种算法,一种是找recall在[0.0:0.1:1.0]这11个位置处的Precision然后算平均
另一种是先找到曲线上所有recall位置(unique),然后再找每个recall上最大的Precision(max),再求平均
计算完每个类的AP之后算一下平均得到mAP
mAP50表示IOU阈值在0.5时的mAP
mAP(不标注thr)的表示对不同阈值(0.50-0.95)下的mAP再取平均
指标

对比实验
- 对比聚两个类还是聚一个类


- 聚类ball query的半径
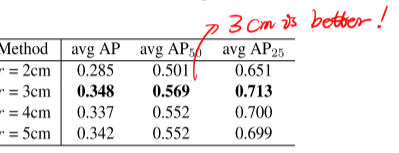
- 运行时间分析
可以看出最前面U-Net最耗时(50%时间)

分析
这个思想在点云实例分割挺新颖的,通过计算质心来聚类,相比于计算embedding看起来更优雅,但是感觉存在以下问题:
- 前面Backbone网络用U-Net进行体素特征提取然后再还原回点云感觉会很耗时间
- 最终的模型可能处于性能的考量,设计了用原始点云和质心点云分别聚两次类,这部分不是很有说服力
- 后面的聚类算法和ScoreNet看起来也是感觉不是很有道理
- 类似的质心聚类思想也在其他地方出现过,但是用在实例分割上真的感觉很合适
对自己而言,这篇论文很友善地给了Pytorch的代码(其他点云实例分割大都是tf实现)
我要想用这个网络做自己的实例分割,需要考虑一下问题
- 计算开销:这里采用了体素化的形式
- 超参数的设置
- 在哪里提取part实例的embedding?
类似的工作
- 3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation(CVPR2020)
- VoteNet
- 3D semantic segmentation with submanifold sparse convolutional networks
- Gs3d: An efficient 3d object detection framework for autonomous driving
- U-net: Convolutional networks for biomedical image segmentation

