DyCo3D: Robust Instance Segmentation of 3D Point Clouds through Dynamic Convolution
论文信息
| 作者 | 作者单位 | 年份 | 会议/期刊名 | 引用量 | 研究方向 |
|---|---|---|---|---|---|
| Tong He;沈春华 | Adelaide | 2021 | CVPR | 2 | 3D实例分割 |
0. TL;DR
We propose instead a dynamic , proposal-free , data-driven approach (labeled DyCo3D) that generates the appropriate convolution kernels to apply in
response to the nature of the instances (Abs )
1. Motivation
Previous top-performing approaches for point cloud instance segmentation involve a bottom-up strategy
includes inefficient operations or complex pipelines , such as grouping over-segmented components , introducing additional steps for refining , or designing complicated loss
functions.The inevitable variation in the instance scales can lead bottom-up methods to become particularly sensitive to hyper-parameter values
2. Previous work
Drawbacks
Previous top-performing approaches for point cloud instance segmentation involve a bottom-up strategy
Including inefficient operations or complex pipelines, such as grouping over-segmented components , introducing additional steps for refining , or designing complicated loss functions .
The inevitable variation in the instance scales can lead bottom-up methods to become particularly sensitive to hyper-parameter values (the performance is sensitive to values of the pre-defined hyper-parameters, which require manual tuning )
heavily reliant on the quality of the proposals , which limits their robustness and can lead to joint/fragmented instances in practice.

3D-MPA: extracts proposals from the predicted instance centroids. Instances are then generated by aggregating proposal-wise embeddings.
PointGroup: generates instances proposals by gradually merging neighbouring points that share the same category label. Both original and centroid-shifted points are explored with a manually specified search radius. A separate model (labelled ScoreNet) is used to estimate the objectness of the proposals.
Dynamic Convolution
主要参考两篇论文:Dynamic filter networks. (NIPS 2016) 、Conditional convolutions for instance segmentation. (ECCV 2020)
Conditional convolutions for instance segmentation 直接从2D迁移到3D效果不好有如下原因:
- it introduces a large amount of computation, resulting in optimization difficulties. (优化难度提升很大)
- the performance is constrained by the limited receptive field and representation capability due to the sparse convolution (感受野大小被稀疏卷积限制了)
3. Method
Summary
Features
propose a novel pipeline tailored to 3D point cloud instance segmentation using dynamic convolution, that we label DyCo3D
propose to encode category-specific context by deploying a lightweight sub-network to explore homogenous points that have close votes for instance centroids and share the semantic
labels.propose to introduce a small transformer to capture a long-range dependency and build high-level interactions among different regions.
Robustness; 对于超参数不敏感
More efficiency
Point of View
To make the kernels discriminative , we explore a large context by gathering homogeneous points that share identical semantic categories and have close votes for the geometric centroids . (聚合属于同一个语义类别且具有相近实例中心的同源点)
Due to the** limited receptive field introduced by the sparse convolution** , a small light-weight transformer is also devised to capture the long-range dependencies and
high-level interactions among point samples.
Overall Architecture
DyCo3D is comprised of three primary components(整体结构):
a backbone network , which is** based on sparse convolution ** for feature extraction, and **contains a light-weighted ** transformer .
A weight generator that responds to the individual characteristics of each instance to dynamically generate the appropriate filter parameters . To make the filters discriminative, a large category-specific context is introduced.
An instance decoder . Instances are separated in parallel , using only three convolution layers, by convolving the generated class-aware filters with position embedded features.

produce instance masks using only a small number of simple convolutional layers.
The associated convolution filters are dynamically generated , conditioned on both spatial distribution of the data and the semantic predictions. (卷积核动态生成,受数据空间分布以及语义分割预测控制)
Backbone
U-Net + Transformer
Transformer
except for the position embedding layer, where the position-sensitive information is **encoded ** as the mean of the pairwise direction vector or relative position.
论文中没有具体写这个transformer加在哪里以及具体细节,推测是在U-Net bottleneck位置上的self-attention
Output by the backbone
语义分割$\mathbf{F}_{\mathrm{seg}} \in \mathbb{R}^{N \times C}$ (apply traditional cross entropy loss)
中心偏移量$\mathbf{O}_{\mathrm{off}} \in \mathbb{R}^{N \times 3}$
$$
\mathcal{L}{\mathrm{ctr}}=\frac{1}{N{v}} \sum_{i=0}^{N}\left|p^{i}+o_{\mathrm{off}}^{i}-c t r_{\mathrm{gt}}^{i}\right| \cdot \mathbb{1}\left(p^{i}\right)
$$
- instance masking $ \mathbf{F}_{\mathrm{mask}} \in \mathbb{R}^{N \times D}$, where D is the dimension of the output channel
Dynamic Weight Generator
To **generate discriminative filters for distinguishing different instances ** we propose to group homogenous points that have close votes for the geometric centroids and
share the category predictions.
instance-aware filters are dynamically generated by applying a small sub-network for large context aggregation
引入这个模块的动机还是稀疏卷积造成的感受野偏小 (impair the method’s ability to exploit large-scale context ),提取cluster级的feature
Grouping points by using a similar strategy to PointGroup
applying a breadth-first searching algorithm to group homogenous points that have identical semantic labels and close centroids predictions.
**Integrates ** large context to generate filters for instances decoding
Due to the removal of the reliance on the quality of the instance proposals, the performance of our method is robust to the pre-defined hyper-parameters
extract instance feature by 3-layer network $G_w(\cdot)$
First, voxelize instance points (14x14x14). The features of each grid is calculated as the average of the point feature $F_b$ within the grid, where $F_b$ is the output of the backbone
aggregate context for cluster. It contains two sparse convolutional layers with a kernel size of 3, a global pooling layer, and an MLP layer. $\mathcal{W}_C^z$

Instance Decoder
- directly append position embeddings in the feature space . (instance cluster中每一个点的位置相对于质心做归一化)
Given a specific category, position representation is critical to separate different instances. (作者认为位置信息对于分隔两个实例来说很关键)
$$
f_{\mathrm{pos}}^{i}=p^{i}-\mathcal{C}_{\mathrm{ctr}}^{z}
$$
- 每个Cluster中每个point的input feature $f_z^i$由$f_{pos}^i$和$f_{mask}^i$拼接(注意$f_z$的维度是$N\times(D+3)$)

decode binary segmentations of instances
Network: The whole decoder contains** three convolution** layers with a kernel size of 1 × 1 . Each layer uses **ReLU ** as the activation function without normalization . $m_{z} \in \mathbb{R}^{N}$
这里的意思是我们将$\mathcal{W}_{\mathcal{C}}^{z}$作为卷积层的参数
$$
177=\underbrace{(8+3) \times 8+8}{\text {conv } 1}+\underbrace{8 \times 8+8}{\text {conv } 2}+\underbrace{8 \times 1+1}_{\text {conv3 }}
$$
$$
m_{z}=\operatorname{Conv}\left(\mathcal{W}{\mathcal{C}}^{z}, f{z}\right)
$$
- mask prediction (Before that, dice loss is also utilized)
$$
\mathcal{L}{\text {mask }}=\frac{1}{Z} \sum{z=1}^{Z} \frac{1}{N_{z}} \sum_{j=1}^{N} \mathbb{1}{l{\mathrm{seg}}^{j}=l_{\mathrm{c}}^{z}} \cdot L_{\mathrm{BCE}}\left(m_{z}^{j}, \hat{m}_{z}^{j}\right)
$$
Training & Post-process
- Total loss
$$
\mathcal{L}=\mathcal{L}{\text {seg }}+\mathcal{L}{\text {ctr }}+\mathcal{L}{\text {mask }}+\mathcal{L}{\text {dice }}
$$
- NMS on the instance binary mask
4. Experiment
Metric
mConv: mConv is defined as the mean instance-wise IoU
mWConv: mWConv denotes the weighted version of mConv
mPrec
mRec
Ablation Study

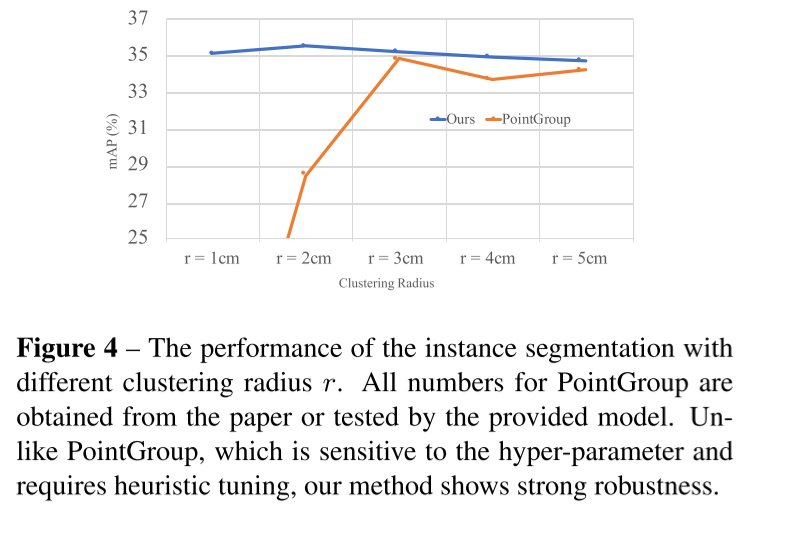
- Efficiency
DyCo3D 0.28s
PointGroup 0.39s
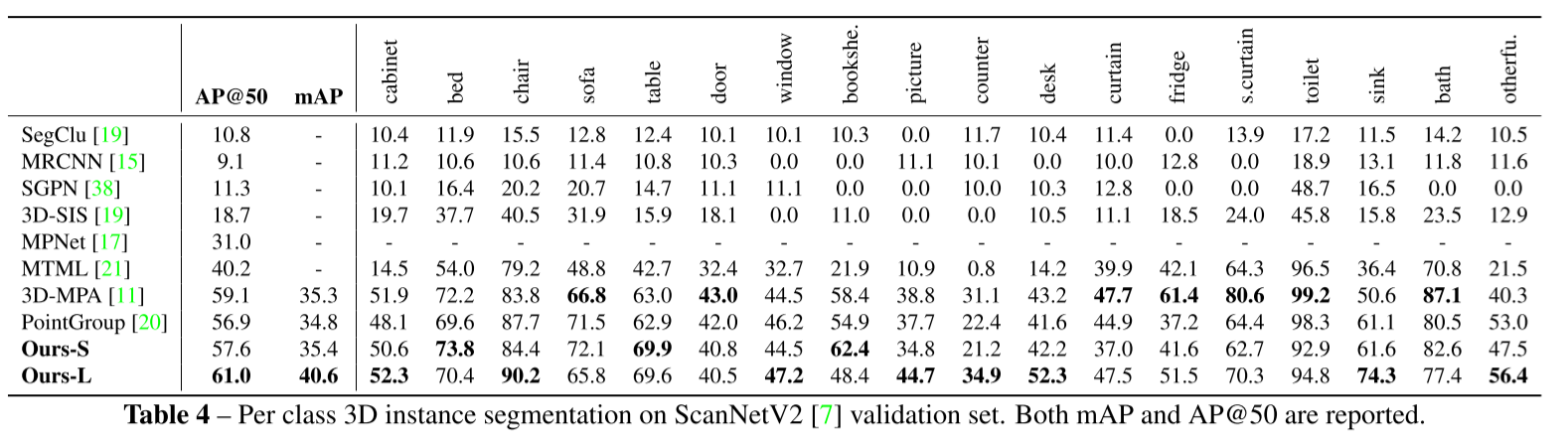
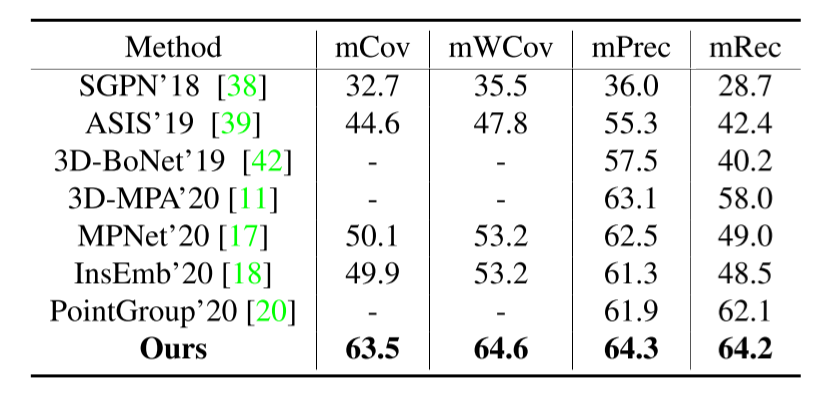
Result


5. Remark
PointGroup基础上提升了效率、精度、鲁棒性
Backbone有改动,引入小的Transformer模块
动态卷积CondInst
instance embedding + mask + NMS方式解决over-seg问题
PointGroup+他们团队之前CondInst